| Module | Module Name | Links | Links | Blake's Links |
| PM | Plant Mantenance | tutorials point | Blake | |
| MM | Material Management | tutorials point Overview | Guru99 | Blake: 1-10 | 11-20 | 21-25 |
| SD | Sales and Distribution | tutorials point Tutorial | Guru99 | Blake |
| PP | Production Planning | tutorials point Tutorial | Guru99 | Blake | 1-7 |
| External Links | ||||
| NewLanguage.html | FICO Module: Blake's 1-28 29-56 57-66 67-83 : Tutorials Point | |||
| Download Info | ABAP Module: Blake's 1-18 19-36 37-52 : Tutorials Point | |||
paragraph
paragraph
paragraph
paragraph
paragraph
paragraph
paragraph
paragraph
paragraph
paragraph
Open SQL indicates the subset of ABAP statements that enable direct access to the data in the central database of the current AS ABAP. Open SQL statements map the Data Manipulation Language functionality of SQL in ABAP that is supported by all database systems.
The statements of Open SQL are converted to database specific SQL in the Open SQL interface of the database interface. They are then transferred to the database system and executed. Open SQL statements can be used to access database tables that are declared in the ABAP Dictionary. The central database of AS ABAP is accessed by default and also access to other databases is possible via secondary database connections.
Whenever any of these statements are used in an ABAP program, it is important to check whether the action executed has been successful. If one tries to insert a record into a database table and it is not inserted correctly, it is very essential to know so that the appropriate action can be taken in the program. This can done using a system field that has already been used, that is SY-SUBRC. When a statement is executed successfully, the SY-SUBRC field will contain a value of 0, so this can be checked for and one can continue with the program if it appears.
The DATA statement is used to declare a work area. Let's give this the name 'wa_customers1'. Rather than declaring one data type for this, several fields that make up the table can be declared. The easiest way to do this is using the LIKE statement.
The wa_customers1 work area is declared here LIKE the ZCUSTOMERS1 table, taking on the same structure without becoming a table itself. This work area can only store one record. Once it has been declared, the INSERT statement can be used to insert the work area and the record it holds into the table. The code here will read as 'INSERT ZCUSTOMERS1 FROM wa_customers1'.
The work area has to be filled with some data. Use the field names from the ZCUSTOMERS1 table. This can be done by forward navigation, double clicking the table name in the code or by opening a new session and using the transaction SE11. The fields of the table can then be copied and pasted into the ABAP editor.
Following is the code snippet −
DATA wa_customers1 LIKE ZCUSTOMERS1. wa_customers1-customer = '100006'. wa_customers1-name = 'DAVE'. wa_customers1-title = 'MR'. wa_customers1-dob = '19931017'. INSERT ZCUSTOMERS1 FROM wa_customers1.
CHECK statement can then be used as follows. It means that if the record is inserted correctly, the system will state this. If not, then the SY-SUBRC code which will not equal zero will be displayed. Following is the code snippet −
IF SY-SUBRC = 0. WRITE 'Record Inserted Successfully'. ELSE. WRITE: 'The return code is ', SY-SUBRC. ENDIF.
Check the program, save, activate the code, and then test it. The output window should display as 'Record Inserted Successfully'.
CLEAR statement allows a field or variable to be cleared out for the insertion of new data in its place, allowing it to be reused. CLEAR statement is generally used in programs and it allows existing fields to be used many times.
In the previous code snippet, the work area structure has been filled with data to create a new record to be inserted into the ZCUSTOMERS1 table and then a validation check is performed. If we want to insert a new record, CLEAR statement must be used so that it can then be filled again with the new data.
If you want to update one or more existing records in a table at the same time then use UPDATE statement. Similar to INSERT statement, a work area is declared, filled with the new data that is then put into the record as the program is executed. The record previously created with the INSERT statement will be updated here. Just edit the text stored in the NAME and TITLE fields. Then on a new line, the same structure as for the INSERT statement is used, and this time by using the UPDATE statement as shown in the following code snippet −
DATA wa_customers1 LIKE ZCUSTOMERS1. wa_customers1-customer = '100006'. wa_customers1-name = 'RICHARD'. wa_customers1-title = 'MR'. wa_customers1-dob = '19931017'. UPDATE ZCUSTOMERS1 FROM wa_customers1.
As UPDATE statement gets executed, you can view the Data Browser in the ABAP Dictionary to see that the record has been updated successfully.
MODIFY statement can be considered as a combination of the INSERT and UPDATE statements. It can be used to either insert a new record or modify an existing record. It follows a similar syntax to the previous two statements in modifying the record from the data entered into a work area.
When this statement is executed, the key fields involved will be checked against those in the table. If a record with these key field values already exist, it will be updated. If not, then a new record will be created.
Following is the code snippet for creating a new record −
CLEAR wa_customers1. DATA wa_customers1 LIKE ZCUSTOMERS1. wa_customers1-customer = '100007'. wa_customers1-name = 'RALPH'. wa_customers1-title = 'MR'. wa_customers1-dob = '19910921'. MODIFY ZCUSTOMERS1 FROM wa_customers1.
In this example, CLEAR statement is used so that a new entry can be put into the work area, and then customer (number) 100007 is added. Since this is a new, unique key field value, a new record will be inserted, and another validation check is executed.
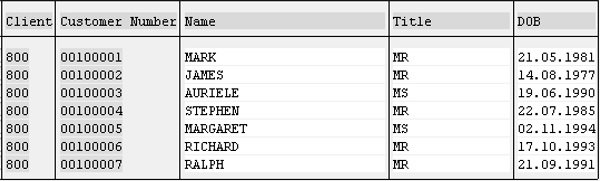
When this is executed and the data is viewed in the Data Browser, a new record will have been created for the customer number 100007 (RALPH).
The above code produces the following output (table contents) −
The term ‘Native SQL’ refers to all statements that can be statically transferred to the Native SQL interface of the database interface. Native SQL statements do not fall within the language scope of ABAP and do not follow the ABAP syntax. ABAP merely contains statements for isolating program sections in which Native SQL statements can be listed.
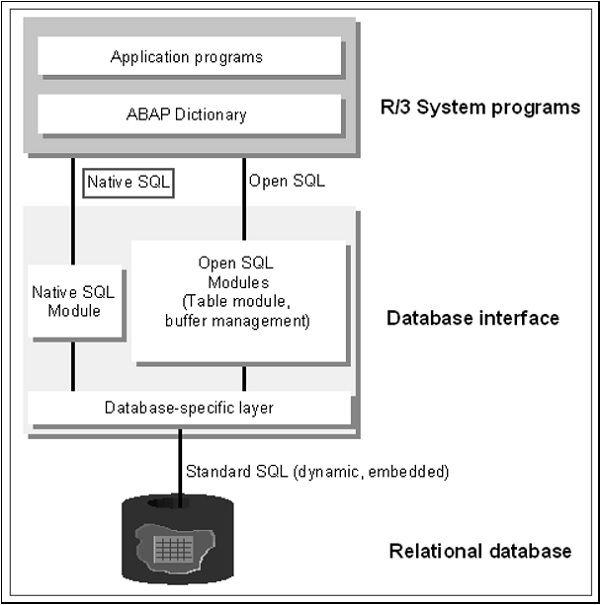
In native SQL, mainly database-specific SQL statements can be used. These are transferred unchanged from the native SQL interface to a database system and executed. The full SQL language scope of the relevant database can be used and the addressed database tables do not have to be declared in the ABAP Dictionary. There is also a small set of SAP specific Native SQL statements that are handled in a specific way by the native SQL interface.
To use a Native SQL statement, you have to precede it with the EXEC SQL statement and end with ENDEXEC statement.
Following is the syntax −
EXEC SQL PERFORMING <form>. <Native SQL statement> ENDEXEC.
These statements define an area in an ABAP program where one or more Native SQL statements can be listed. The statements entered are passed to the Native SQL interface and then processed as follows −
All SQL statements that are valid for the program interface of the addressed database system can be listed between EXEC and ENDEXEC, in particular the DDL (data definition language) statements.
These SQL statements are passed from the Native SQL interface to the database system largely unchanged. The syntax rules are specified by the database system, especially the case sensitivity rules for database objects.
If the syntax allows a separator between individual statements, you may include many Native SQL statements between EXEC and ENDEXEC.
SAP specific Native SQL language elements can be specified between EXEC and ENDEXEC. These statements are not passed directly from the Native SQL interface to the database, but they are transformed appropriately.
SPFLI is a standard SAP Table that is used to store Flight schedule information. This is available within R/3 SAP systems depending on the version and release level. You can view this information when you enter the Table name SPFLI into the relevant SAP transaction such as SE11 or SE80. You can also view the data contained in this database table by using these two transactions.
REPORT ZDEMONATIVE_SQL. DATA: BEGIN OF wa, connid TYPE SPFLI-connid, cityfrom TYPE SPFLI-cityfrom, cityto TYPE SPFLI-cityto, END OF wa. DATA c1 TYPE SPFLI-carrid VALUE 'LH'. EXEC SQL PERFORMING loop_output. SELECT connid, cityfrom, cityto INTO :wa FROM SPFLI WHERE carrid = :c1 ENDEXEC. FORM loop_output. WRITE: / wa-connid, wa-cityfrom, wa-cityto. ENDFORM.
The above code produces the following output −
0400 FRANKFURT NEW YORK 2402 FRANKFURT BERLIN 0402 FRANKFURT NEW YORK
Internal table is actually a temporary table, which contains the records of an ABAP program that it is being executed. An internal table exists only during the run-time of a SAP program. They are used to process large volumes of data by using ABAP language. We need to declare an internal table in an ABAP program when you need to retrieve data from database tables.
Data in an internal table is stored in rows and columns. Each row is called a line and each column is called a field. In an internal table, all the records have the same structure and key. The individual records of an internal table are accessed with an index or a key. As internal table exists till the associated program is being executed, the records of the internal table are discarded when the execution of the program is terminated. So internal tables can be used as temporary storage areas or temporary buffers where data can be modified as required. These tables occupy memory only at run-time and not at the time of their declaration.
Internal tables only exist when a program is running, so when the code is written, the internal table must be structured in such a way that the program can make use of it. You will find that internal tables operate in the same way as structures. The main difference being that structures only have one line, while an internal table can have as many lines as required.
An internal table can be made up of a number of fields, corresponding to the columns of a table, just as in the ABAP dictionary a table was created using a number of fields. Key fields can also be used with internal tables, and while creating these internal tables they offer slightly more flexibility. With internal tables, one can specify a non-unique key, allowing any number of non-unique records to be stored, and allowing duplicate records to be stored if required.
The size of an internal table or the number of lines it contains is not fixed. The size of an internal table changes according to the requirement of the program associated with the internal table. But it is recommended to keep internal tables as small as possible. This is to avoid the system running slowly as it struggles to process enormous amounts of data.
Internal tables are used for many purposes −
They can be used to hold results of calculations that could be used later in the program.
An internal table can also hold records and data so that this can be accessed quickly rather than having to access this data from database tables.
They are hugely versatile. They can be defined using any number of other defined structures.
Assume that a user wants to create a list of contact numbers of various customers from one or several large tables. The user first creates an internal table, selects the relevant data from customer tables and then places the data in the internal table. Other users can access and use this internal table directly to retrieve the desired information, instead of writing database queries to perform each operation during the run-time of the program.
paragraph
paragraph
paragraph
paragraph
paragraph
paragraph